


Zbieranie linków i tworzenie zestawień - jak to robię
Tworzenie takich zestawień nie jest prostą sprawą - wymaga to włożenia pewnego wysiłku. W tym artykule przedstawię jak to u mnie wygląda od kuchni, czyli tworzenie zestawień, ale będzie też trochę informacji jak działa ta strona, aby móc zrozumieć automatykę stojącą za tworzeniem takich zestawień. Mam nadzieję, że artykuł będzie jakąś inspiracją dla niektórych i jednocześnie pokaże, że zbieranie linków nie jest takie proste, na jakie wygląda.
- Czasy prehistoryczne
- Moja strona
- Hugo
- Wersjonowanie w gicie
- Raindrop
- Generator stron
- Wykop.pl
- Integromat
- Plany
Czasy prehistoryczne
Zaczęło się w serwisie wykop.pl - polecam zerknąć tam do archiwalnych wpisów, bo najpierw powstał kanał na YouTube, a potem wpisy na wykopie. Generalnie na samym początku linki były zbierane do pliku tekstowe, później do repozytorium na GitHub, a więc zaczynałem od spraw naprawdę prostych.
Moja strona
Moja strona, czyli devopsiarz.pl jest prowadzona w tej dziwnej (obecnie) filozofii, że jest centrum wszystkiego. Wszystkie ewentualne sociale są jedynie “dodatkiem”. Czyli nigdy nie będzie tak, że będzie jakiś artykuł, np. na twitterze czy facebooku, a nie będzie go jednocześnie na stronie - strona jest absolutnie najważniejsza i to ona ma mieć wszystko.
Pomijamy oczywiście mój kanał na YouTubie, który zacząłem prowadzić przed stroną, ale obecnie generalnie zasada jest taka, że najpierw coś musi pojawić się na stronie, a dopiero potem będę się zastanawiał czy np. powinno wylądować gdzieś indziej jeszcze. Po prostu dużo czytam historii, że ludzie opierają nawet swoje biznesy np o strony na facebookach, czy gdzieś, rozwijają tam zasięgi, po czym, jak dostają jakąś blokadę z jakiekolwiek powodu, to mają spory problem i może być płacz. Własna strona, na własnym serwerze (VPS) z osobnym rejestratorem domen aniżeli dostawca VPS, to jest jednak duża pewność, że żaden Janusz moderatorstwa danego sociala nie zrzuci Twojego biznesu z rowerka, pamiętaj o tym.
Hugo
Hugo jest świetnym generatorem stron statycznych, który odpowiada za wygenerowanie strony, którą właśnie czytasz. Czym jest generator stron statycznych? Najprościej: na podstawie specjalnych plików-szablonów, generuje statyczną stronę z kodem HTML/CSS/JS. Tylko tyle i aż tyle. Wytłumaczę na przykładzie.
Porównam z Wordpressem, ale zamiast Wordpressa można wsadzić w zasadzie dowolną aplikację z modelu (L)AMP (zazwyczaj PHP+MySQL+Apache). W przypadku Wordpressa jest aplikacja (jako całość), która dostaje żądanie od serwera Ciebie, za odbiór tego żądania odpowiada serwer www (przykładowo) i “przesyła go” dalej, do właściwej aplikacji PHP. Ta aplikacja analizuje żądanie, pobiera żądane dane z bazy danych, po czym generuje kod HTML, który odeśle serwerowi WWW, a który finalnie odeśle go Tobie.
Finalnie, Twoja przeglądarka otrzyma kod HTML i wyświetli Ci właściwą stronę na podstawie tego kodu. Jak zatem widać, mamy tutaj wiele elementów systemu: serwer www, aplikacja php i baza danych. To jest taki w miarę prosty stack technologiczny takiej strony, bo może tu być wiele innych elementów, dodatkowe bazy, cache, itp.
W przypadku statycznego generatora stron, mamy pliki-szablony, które same w sobie stroną nie są, ale przechowują jakąś zawartość, która w fazie generowania strony taką stroną (w postaci pliku HTML/CSS/JS) dopiero się stanie. Czyli można to określić tak, że odwiedzając stronę stworzoną za pomocą generatora statycznych stron, nie “odwiedzasz” ani nie “pytasz” o nic generatora, odwiedzasz to, co on już wygenerował w przeszłości, czyli finalne, statyczne pliki strony. W tym przypadku Twoje żądanie obsługuje tylko i wyłącznie serwer WWW, który stwierdza, że ma statyczne pliki i Ci je po prostu serwuje, nie komunikuje się z żadnymi dodatkowymi elementami lub bazą danych. A statyczne pliki dla serwera WWW to prostota do obsługi, nie potrzeba żadnych dodatkowych konfiguracji, pluginów, modułów itp.
Oczywiście to jest bardzo uproszczona zasada działania generatora stron statycznych i na pierwszy rzut oka mogłoby się wydawać, że używanie takiego generatora nie ma większego sensu - mamy tylko pliki, które już “nic nie robią”, w przypadku np. Wordpressa możemy dowolnie “odpytywać” aplikacje, bo cały czas gotowa ona nam zwrócić jakieś dane z bazy, a pliki statyczne są już takimi danymi i nic więcej nie zwracają, bo nie są w stanie (poza faktem, że mogą mieć kod JS, który gdzieś może się odwoływać)
Trochę to prawda, ale też nie do końca, bo generator stron statycznych jest w stanie tak sprytnie generować strony, nawet bardzo skomplikowane, że mamy wrażenie, iż mamy do czynienia z jakąś taką aplikacją typu Wordpress - generowanie kategorii, tagów, różnych linków zwrotnych itp - te i wiele innych rzeczy jest w stanie zrobić generator stron statycznych.
Wersjonowanie w gicie
Strony oparte o generator stron statycznych mają kilka ciekawych zalet, ale wymienię tutaj jedną, która ma znaczenie w kontekście tego artykułu: pliki-szablony to po prostu pliki markdown (md) i bardzo ładnie można je wersjonować w dowolnym systemie kontroli wersji, ja np. używam gita.
Daje mi to tę zaletę, że jak kiedyś Hugo mi się znudzi, to mogę użyć zupełnie innego generatora, bo te plików wśród generatorów są podobnie obsługiwane. To tak, jakby chcieć z Wordpressa przejść na Drupala (i odwrotnie) i zupełnie nie martwić się, że to dwa niekompatybilne systemy z niekompatybilnymi bazami danych.
Inna zaleta w związku z używaniem systemu wersji: mogę “wrócić” do którejkolwiek wcześniejszej wersji artykułu na stronie. Czyli, jeżeli mam stronę, która często jest aktualizowana, nawet przez kilka osób, to dzięki systemowi kontroli wersji mogę dokładnie sprawdzić kto dodał jakąś treść, lub przywrócić “obraz” strony z przeszłości, bez utraty “obrazu” aktualnego. W aplikacjach opartych o PHP i bazy danych jest to bardzo trudne i najczęściej musi być obsługiwane przez aplikację samą w sobie, tutaj o to dba system kontroli wersji, czyli w moim przypadku git.
Generalnie dzięki wersjonowaniu można pracować nad stroną WWW jak nad każdym innym kodem. Poniżej zrzut prezentuje pisanie nowego artykułu na zupełnie osobnym branchu, który kiedyś zostanie zmergowany do mastera (z mastera generowane są pliki strony)
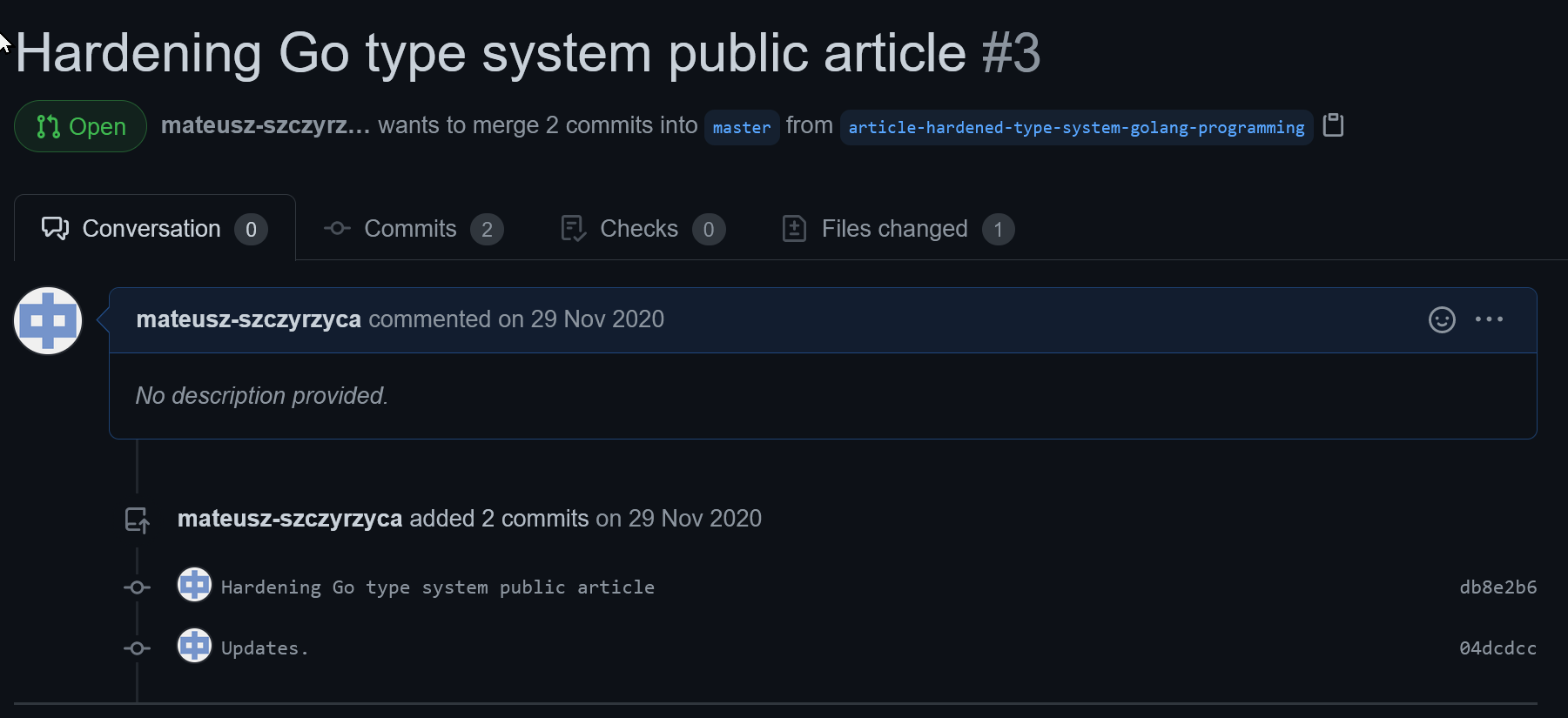
A tutaj zrzut w trakcie pisania tego artykułu - jak widać w użyciu jest normalny edytor tekstu. Takie o to możliwości dostajemy, gdy mamy stronę opartą o generator stron statycznych wraz z wersjonowaniem w systemie kontroli wersji.
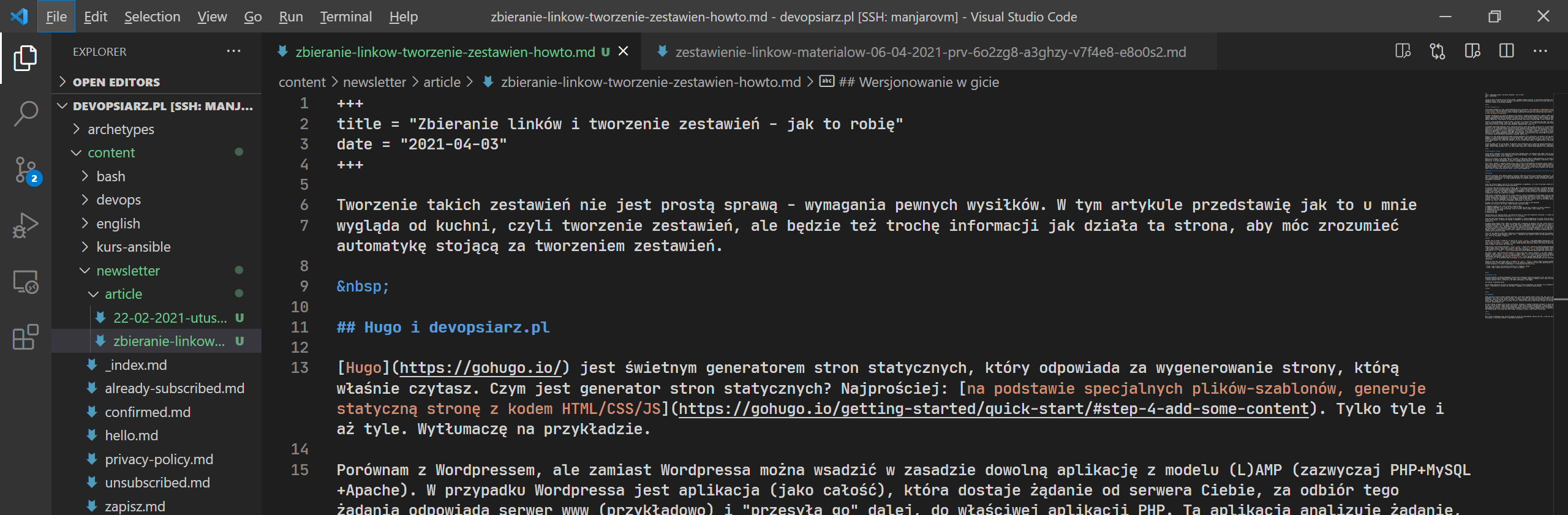
Wykorzystując generator stron statycznych oraz git jako system kontroli wersji (w postaci serwisu GitHub), gdy chcę dodać, zmienić lub usunąć artykuł, po prostu wrzucam/edytuję do repozytorium związanym ze stroną odpowiedni plik *.md i do 5 minut od wysłania takiego pliku, na serwerze devopsiarz.pl, generator stron statycznych użyje tego nowego pliku, aby wygenerować aktualną stronę.
Dociekliwi mogą się zastanawiać co będzie jak usługa tzw. trzecia, czyli GitHub, padnie? Odpowiadam: skutek będzie tylko taki, że strona się nie zaktualizuje - bo pliki dotychczas wygenerowane na niej zostają, dopiero gdy pojawiają się jakieś nowe, generator Hugo generuje całą stronę od nowa (zajmuje to ułamki sekund)
Raindrop
Pierwszym narzędziem, które wydatnie pomaga w tworzeniu linków jest usługa Raindrop, wersja płatna - jest to usługa podobna do Pocket znanego z Firefoksa, gdzie dodajemy sobie “ulubione” strony, tak w wielkim skrócie mówiąc. Ta usługa posiada aplikacje na wszystkie systemy + wtyczki na wszystkie liczące się przeglądarki internetowe.
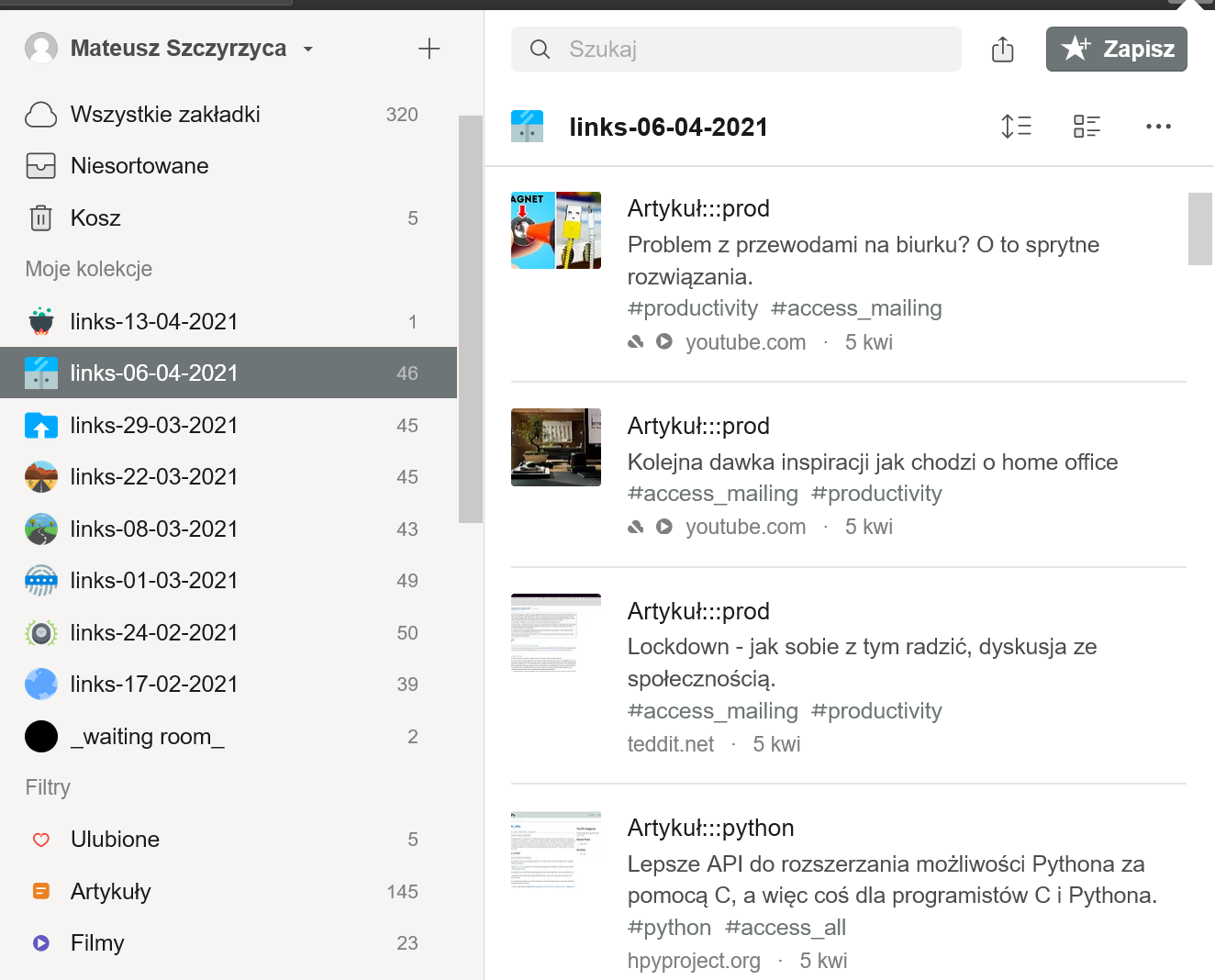
Teraz ktoś słusznie zapyta: czym się to różni od bookmarków z przeglądarki, że aż musi to być jakaś osobna usługa, do tego płatna? Zatem już przygotowałem stosowne wyjaśnienie.
Po pierwsze: tego typu aplikacja działa wszędzie, gdzie jej aplikacje klienckie działają, w przypadku Raindropa czy Pocketa to wszystkie liczące się systemy mobilne i desktopowe - i zawsze mamy dostęp do tej samej zawartości. Aby odtworzyć jej zachowanie w postaci synchronizowania benchmarków w przeglądarce, trzeba “logować” się do przeglądarki (do Gmaila jak w Chrome, synch w Firefox), jak wiemy to logowanie do przeglądarki nie wszyscy stosują, a do aplikacji typu Pocket czy Raindrop zalogować się trzeba, aby w ogóle móc ją używać.
Druga sprawa: przeglądarki raczej nam nie zrzucą zawartości offline (przynajmniej nie jak dodamy stronę do ulubionych), a raindrop nam to zrobi automatycznie i na życzenie. I tu moim zdaniem zarysowuje się główna różnica pomiędzy takimi usługami, a gołymi benchmarkami w przeglądarce: stronę dodaną do Raindrop mogę mieć w wersji offline, z obrazkami, lub w wersji do czytania. Co tylko mnie odpowiada. Czyli jeżeli dodana stronę za parę dni zniknie z sieci lub nie będzie działać, ja wciąż będę miał jej “obraz”, będę mógł go przeglądać, przeszukiwać i co tylko chcę.
No dobra, tyle tytułem porównania do ulubionych, ale co właściwie daje mi taki Raindrop? Spisałem więc możliwości tej usługi z punktu widzenia tworzenia linków:
- dodawanie kategorii (np. linki na dzień 1 Kwietnia 2021)
- dodawanie podkategorii (np. linki do stron tylko na wykop spośród tych w kategorii na dzień 1 kwietnia)
- tagowanie stron (np. tylko dla mailingu, tylko na stronę, tylko na wykop, linux, devops, itp)
- przeszukiwanie wszystkiego
- dostęp przez RSS
- dostęp przez API
Tych możliwości jest znacznie więcej, ale wymieniłem tylko te, które mnie najbardziej interesują. A z punktu tworzenia zestawień zwłaszcza interesują mnie punkty 1, 2, 3 i 6 zwłaszcza.
Czyli mam swoje konto Raindrop i mam wtyczkę do przeglądarki i jestem zalogowany do tej usługi. Teraz załóżmy znalazłem stronę, która uważam, że powinna się znaleźć w zestawieniu. Za przykład weźmy jeden z artykułów na mojej własnej stronie devopsiarz.pl.
Za pomocą wtyczki dodaję stronę, nadaję jej stosowny opis, przypisanie do kategorii oraz tagi, dzięki którym reszta mojej automatyki będzie wiedziała jak i gdzie wrzucić taką stronę. Z tego punktu widzenia tu moja praca się kończy: wcześniej korzystałem z plików *.md na githubie, ale problem z tym rozwiązaniem był taki, że trzeba było tam ręcznie przeklejać linki - generowało to sporo błędów, czasem niewłaściwe linki lądowały na niewłaściwych pozycjach itp. Z usługą typu Raindrop nie mam tego problemu: jeśli wszedłem na jakąś stronę i byłem w stanie ją zapisać w Raindrop, to link na 100% jest poprawny i jedyne co muszę, to skupić się na opisie strony i nadaniu jej właściwych tagów. To znaczne ułatwienie pracy w stosunku do używania gołych plików na GitHub.
Czyli jak chcę dodać do linków https://devopsiarz.pl/programowanie-w-go/golang-packages-dzielimy-nasz-program-na-pakiety/ stronę, to klikam w ikonkę Raindrop i potem Dodaj - raindrop od razu “pobiera” stronę, po czym pozwala mi edytować tytuł i opis, które już sam pobrał i uzupełnił.
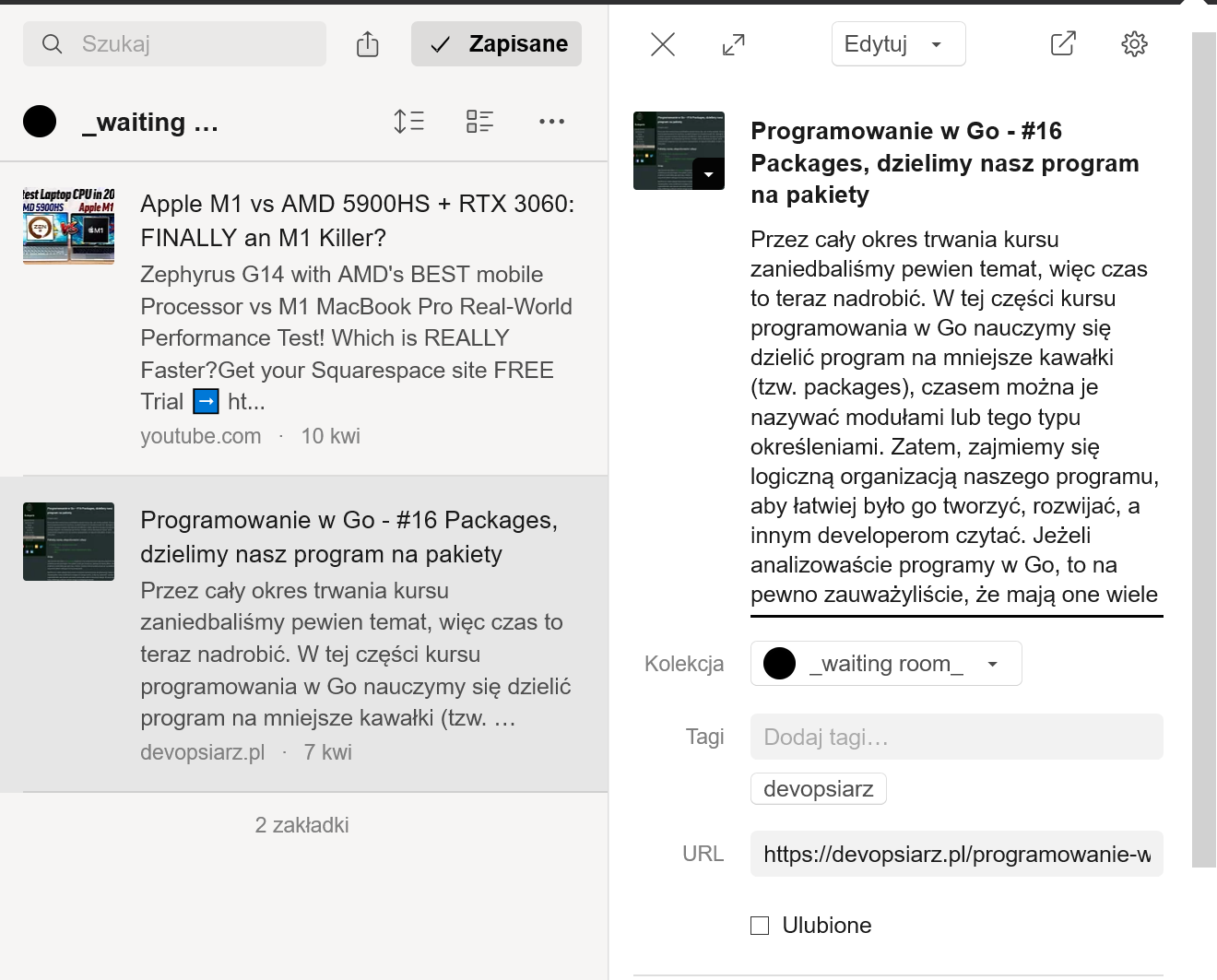
Ponieważ jest to artykuł o języku Go, to tytułuję go Artykuł:::golang, a pod spodem dodaję stosowny opis, np: W jaki sposób dzielimy program w Go na pakiety. Oczywiście mógłbym równie dobrze zostawić automatycznie pobrany tytuł i opis, ale skoro czytasz ten artykuł, to zakładam, że w jakiś sposób doceniasz moje opisy linków, więc raczej te opisy edytuję i opisuję swoimi słowami o czym artykuł lub strona jest.
Słowo jeszcze o tej dziwnej konstrukcji Artykuł:::golang - dzięki niej, program do automatycznego generowania strony z linkami zbiera tytuły w takiej formie, to dzięki temu wie, że jest to Artykuł (czasem może być GitHub, Twitter, YouTube itp - aby czytający wiedział, gdzie link prowadzi), który należy do kategorii golang (na docelowej stronie jest to finalnie zamieniane na Go) - zatem ::: jest tu niczym innym jak prostym separatorem oddzielającym typ linka od jego kategorii
Jak chodzi o tagi - tagi teoretycznie decydują, czy dana strona jest z jakiejś kategorii, w tej chwili jednak, używana jest kategoria z opisu w postaci CotoJest:::kategoria zamiast tagów - to się w przyszłości może zmienić, natomiast bardziej przydają się do określenia, czy link jest ogólnodostępny (#access_all), czyli, że każdy może go dostać lub np. tylko dla subskrybentów newslettera (wtedy jest tag #access_mailing). Jeżeli omyłkowo podam dwa tagi #access_all i #access_mailing, bo sam Raindrop tego nie sprawdza, to link jest traktowany jako dostępny tylko dla subskrybentów newslettera.
Ponadto są inne tagi, którę będę używał w socialach, np: #daily, #weekly że mogę w danych socialach automatycznie umieszczać linki z takimi tagami codziennie, lub raz na tydzień itp. Dodatkowo są tutaj tagi reprezentujące te social media, na które zestawienia i artykuły są publikowane. Ta funkcjonalność umożliwi mi np:
- strony z tagu X umieść na wszystkich socialach raz w tygodniu z opisem
- strony z tagu Y umieść tylko na socialu Z i tylko raz dziennie
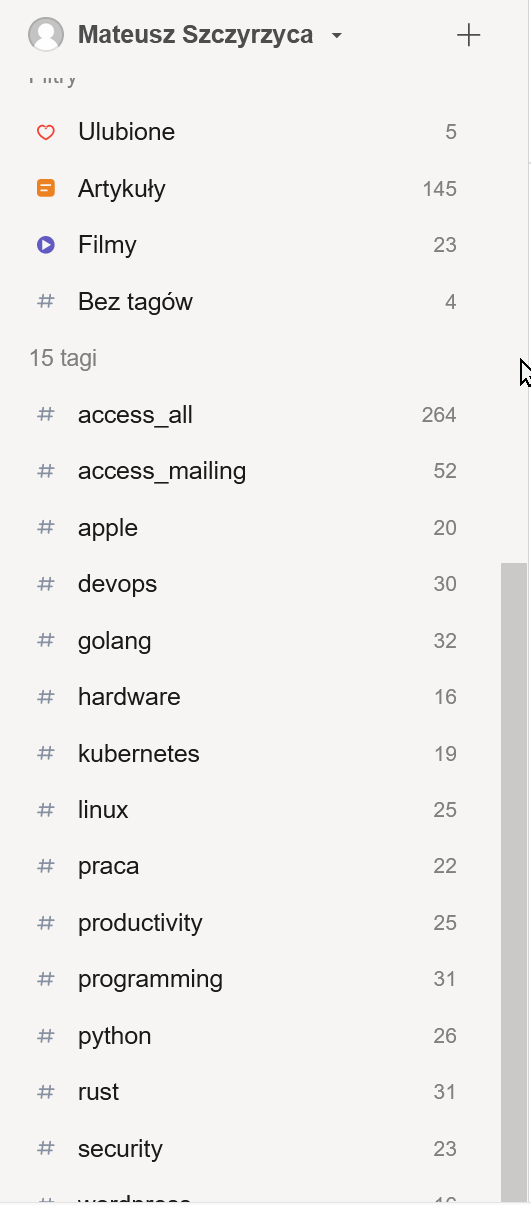
Jak widac na powyższym screenie, dzięki Raindropowi mam listę stron, które posiadam oraz ile stron ma przypisany jaki tag, więc mogę szybko zobaczyć i stwierdzić - o Kubernetesie mam mało linków, bo 19, muszę wrzucać więcej, bo np. o języku Go mam aż 32.
Generator stron
Kolejnym elementem w układance pomagającej tworzyć takie zestawienia linków jest generator stron. Nie wiem czy to właściwe określenie tego narzędzia, ja jednak użyję tego zwrotu. Jest to mój program napisany w Pythonie, który łączy się po API do Raindropa i pobiera zapisane strony z wszelkimi na ich temat informacjami, w tym tagami.
Ten program na podstawie opisów z raindropa i tagów oraz korzystając z własnych szablonów generuje docelowe strony z linkami.
Na tym etapie kompletnie nie muszę się martwić kwestią czy linki są prawidłowe, czy działają, czy nie pomieszałem linka i opisu - w Raindropie już wszystko jest pukładane i otagowane, więc pozostaje jedynie pobrać za pomocą parametru do API (którym jest nazwa kolekcji) i po chwili mamy wygenerowane kilka plików
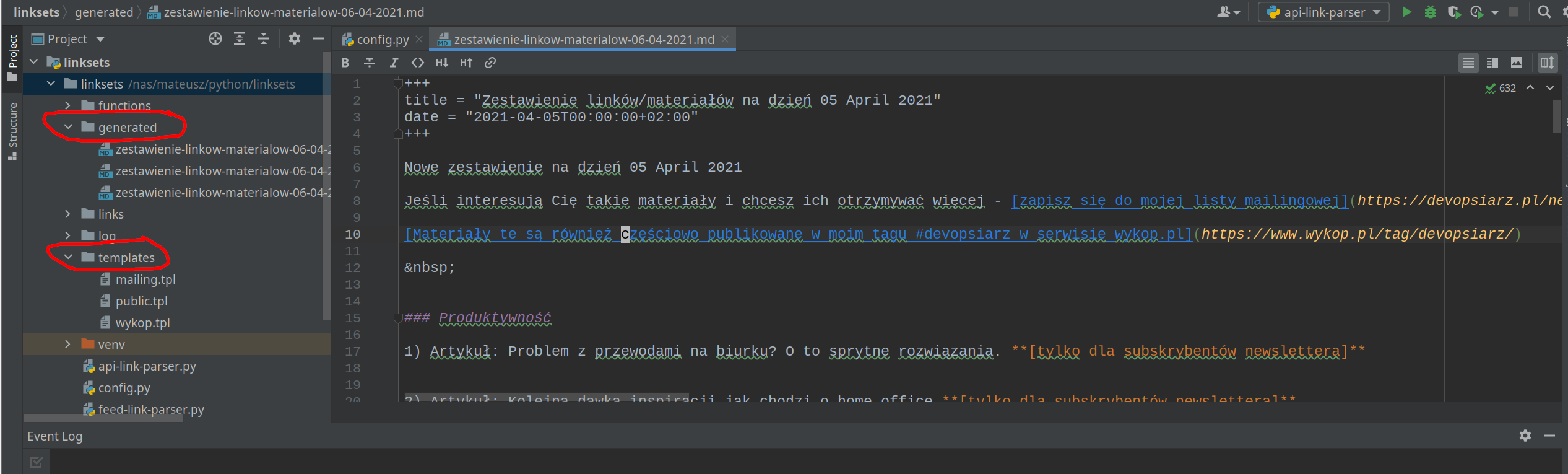
Na powyższym screenie widać PyCharma z otwartym programem do generowania stron i strukturą jego katalogów - katalog generated zawiera wygenerowane pliki *.md dla hugo: jedną dla subskrybentów, drugą dla świata. W tej drugiej część linków jest niedostępna - jest to oceniane na podstawie tagów #access_all lub #access_mailing, które są przypisane w Raindropie.
W zasadzie te szablony dla Hugo są “gotowe”, mógłbym je od razu wrzucać do repozytorium celem aktualizacji mojej strony, ale dodaję jeszcze własny opis na nich i to jedyna manuala część w tym momencie.
W kolei w katalogu templates są proste szablony poszczególnych stron, które są później wypełniane właściwymi danymi. Jak tutaj widać, w tej chwili publikuję dla subskrybentów, dla świata oraz na wykop.pl - w związku z tym każda z tych stron ma swój własny szablon. Strona na wykop.pl nie jest generowana i używana w ramach strony devopsiarz.pl - to tylko treść, która jest wklejana później do wpisów na wykopie.
Szablony są oparte o Template strings w Pythonie i są dostępne w bibliotece standardowej Pythona, to bardzo prosty silnik szablonów i całkowicie wystarczający.
Podsumowując - generator stron pozwala mi tworzyć strony z linkami przeznaczone dla różnych miejsc, mam tu nieskończone możliwości dzięki szablonom i tagom. Obecnie jest hostowany na moim domowym serwerze NAS, bo zwyczajnie rzadko jest uruchamiany (na czas generowanie zestawień). W przyszłości nie wykluczam, że będzie on hostowany na jakimś VPSie, nie wykluczam również jego opublikowania na GitHubie, ale to jak, poprawię kod, bo trochę brzydki jest.
Wykop.pl
Moje zestawienia rozpoczęły się od wpisów na mikroblogu na wykopie i tam ewoluowały, nim finalnie zdecydowałem się je publikować również na mojej stronie. To też wykop zasługuje tutaj na specjalną sekcję.
Jak już zapewne wiesz z poprzedniej sekcji, jest zupełnie osobna strona szablonowa dla wykopu - zawiera odpowiednie dla wpisu na wykop tagi, teksty itp. I też dodawanie wpisów jest zautomatyzowane dzięki bibliotece kolegi krasnoludkolo - wykop-sdk-reborn, który zdecydował się popracować nad nią w pojedynkę. W ogóle polecam przeglądnąć repozytorium krasnoludkolo, bo pracuje on tam nad wieloma innymi projektami związanymi z wykopem.
Na wykopie wszyscy, którzy obserwują pewne tagi lub mój tag powinni zobaczyć nowy wpis. Jest jednak grupa użytkowników, która woli być tzw. wołana do nowych wpisów. Wołanie to wspomnienie czyjegoś nicka we wpisie, wskutek czego taka osoba dostanie powiadomienie na wykopie jakby miała jakąś nową wiadomość. Dawniej wołanie było realizowane przez osobną stronę, która nazywa się mirkolisty - logowało się na nią za pomocą konta na wykop i można było mieć swoją listę wołanych.
Jednak mirkolisty finalnie przestały działać, legendy głoszą, że to przez nowe API. Pojawiła się więc potrzeba jakiegoś zamiennika dla funkcjonalności, którą oferowały, dlatego napisałem własną wołaczkę, która analizuje plusy pod kilkoma ostatnimi wpisami i na podstawie zadanych kryteriów (np. ilość plusów od danej osoby) decyduje, czy wołać czy nie wołać taką osobę do kolejnego wpisu.
Wołaczka została przeze mnie udostępniona na GitHubie i jest dostępna dla wszystkich, którzy chcieliby ją skonfigurować i użyć do swoich potrzeb.
Podsumowując zarówno publikowanie wpisu jak i wołaczka są zintegrowane w ramach jednego programu w Pythonie i jeśli tylko mam
nowe zestawienie w katalogu generated, odpalam go i zapominam o sprawie, bo wiem, że w ciągu 1 minuty będzie wpis + wpis wołający.
Integromat
Kiedy powstanie wreszcie artykuł dostępny publicznie, każdy autor takiego artykułu raczej chce, aby świat o nim się jakoś dowiedział. Jeśli jakiś autor twierdzi inaczej, to kłamie - nikt sobie nie pisze tylko dla siebie artykułów dostępnych publicznie, tylko właśnie dla innych. Dla siebie, to piszemy notatki, które zazwyczaj dostępne są tylko dla nas. A zatem, pisząc artykuł chcemy, aby świat o nim jakoś usłyszał. Techniki działania są tutaj różne, od spamu, po informowanie na socialach, pozycjonowanie itp.
Na chwilę obecną, prowadzę profil strony na Twitterze, Facebooku i Linkedin. Aczkolwiek “prowadzę” to dosyć mocne określenie, gdyż patrz: strona jest najważniejsza - pierwsza sekcja tego artykułu.
Kiedy napiszę swój artykuł, który stanie się publicznie dostępny, a zatem stanie się dostępny przez kanał RSS, wówczas, dzięki usłudze Integromat (konto płatne), ten RSS jest zczytywany i automatycznie jest publikowany na wszystkich podlinkowanych socialach, o których wspomniałem: Facebooku, Twitterze i Linkedin. Dochodzi tu ponadto jeszcze mój kanał na Discord, tam też już mam jakąś społeczność. Zajawka artykułu, w generatorze Hugo jest tym krótkim opisem i ten krótki opis jest używany w socialach to opisu o czym artykuł właśnie jest.
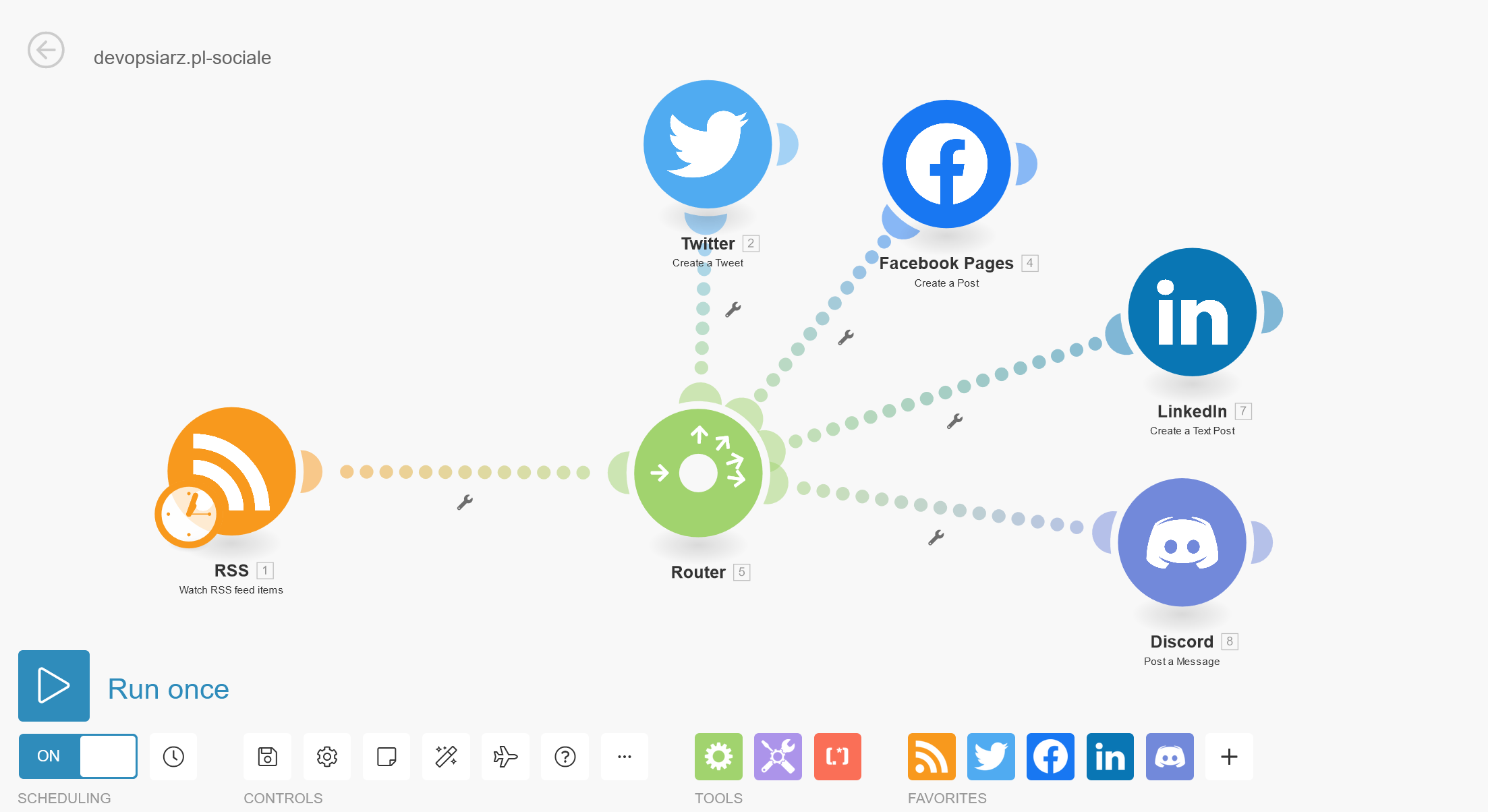
To zdjęcie z tego, jak to wygląda w Integromacie. Integromat jest świetny w tych sprawach, ale używam go też do wielu innych rzeczy, np. do monitorowania strony devopsiarz.pl. To jak użyjesz tę świetną usługę no code zależy tylko od Ciebie, ale możliwości są spore. Zastanawiałem się nad rozwiązaniem podobnym self hosted, niemniej jednak stwierdziłem, że te ~35 PLN co miesiąc nie zrujnuje mnie finansowo, a rozwiązanie self hosted też trzeba gdzieś hostować, jeśli nie w domu (co tutaj jest bez sensu) to z 10 PLN z kieszeni i tak zniknie.
Plany
Mam w planie rozbudowanie tego grajdołka. Pierwszą sprawą są strony dla subskrybentów, obecnie jest tak, że jak ktoś dołączy “później” do mailingu, to nie będzie wiedział o poprzednich materiałach dopóki o nich nie wspomnę. Wiem o tym problemie i pracuję nad nim.
Jestem w trakcie testów tego rozwiązania bazującego na webserwerze, którego używam - caddy. Caddy jest świetny (polecam wszystkim, którzy zatrzymali się w erze Apache lub nginx) i w zasadzie nie muszę martwić się o tak prozaiczne sprawy jak certyfikat TLS dla mojej strony. A ponieważ strony dla subskrybentów, to zwykłe pliki statyczne, można pokusić się o proste rozwiązanie, które udostępni je wszystkim subskrybentom po zalogowaniu.
Druga sprawa - tracker linków, który piszę, to rozwiązanie, które wydatnie pomoże mi śledzić lubiane przez ludzi linki bez konieczności angażowania czegokolwiek poza klikaniem w nie. Pewna jego część jest już gotowa, ale ze względu na pracę dla klienta trochę odwlekam jego skończenie. Ponado tracker linków pozwoli mi bardzo rozszerzyć oprogramowania do newslettera, którego używam - sendy. Niestety to oprogramowanie ma spory dług techniczny i rozglądam się za innymi, lepszymi alternatywami self hosted, aby nie kupować kolejnej usługi SaaS, ale definitywnie tracker linków dużo mi w nim ułatwi.