


System śledzenia live - wnioski po dwóch streamach!
Czas na wstępne podsumowanie podsumowanie 1-szego live, a w zasadzie dwóch live, ponieważ kolega Marcin z kanału TORGiren, nagrał “live-odpowiedź” i jego szybki sposób na taką aplikację, przynajmniej na część skracającą, zliczającą linki. Ponieważ moja sesja Event Stormingu się nie skończyła, ze względu na brak czasu, postanowiłem, że przedstawię szybkie podsumowanie startu projektu i opiszę skrótowo propozycje moje i Marcina.
Tutaj dowiesz się więcej o założeniach projektu, jeśli jeszcze ich nie znasz
Tutaj odpowiedź Marcina z kanału TORGiren DevOpses dzień później
Na wstępnie podziękowania dla Marcina za chęć “partycypacji” w pomysłach i nagrania swojego live jak i dla wszystkich, którzy udzielali są na którejś z tych transmisji.
Założenia
Aplikacja powinna być prosta, w miarę tak prosta jak to możliwe, przy czym “prosta” jest to rozumiane jako nie tylko prostota jej działania, ale też prostota użytego stacku technologicznego i jego ewentualnego później “wystartowania” gdzieś.
Powinna zapewniać minimalne skalowanie, tj. jak będziemy mieć kres jej “mocy” powinno nam się udać ją prosto “rozrzucić” na większej ilości serwerów, bez konieczności jej przepisywania od nowa. :-)
Powinna zapewniać minimalną persystencję danych, czyli pad/zawieszenie się aplikacji nie powinien być tożsamy z koniecznością budowania bazy linków od nowa.
Aplikacja będzie wystawiona na “świat” - to oznacza, że należy też pomyśleć o jej bezpieczeństwie, a nie tylko “skracaj co przyjdzie i olewaj wszystko”. Czyli minimalna higiena security powinna być zachowana.
Podejście TORGirena
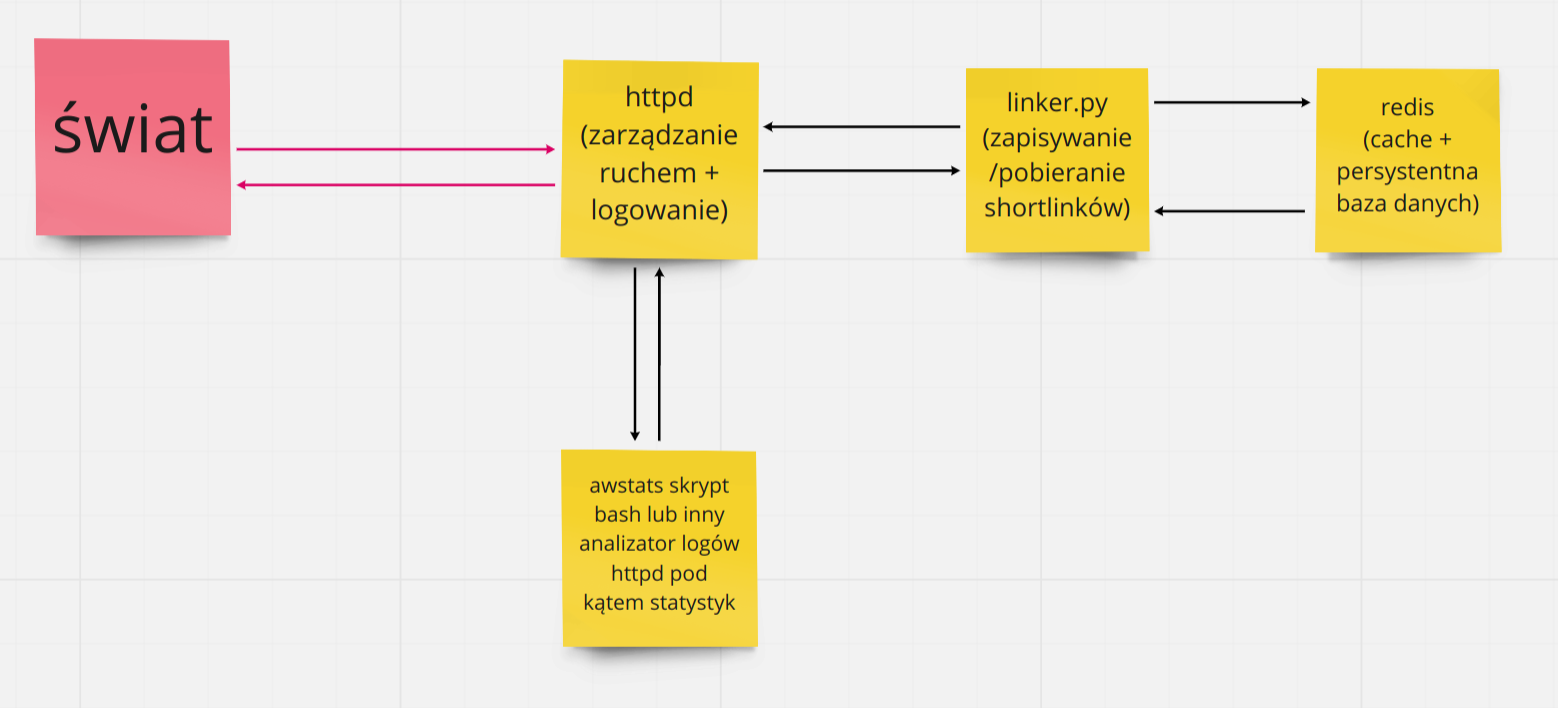
Marcin proponuje httpd (tutaj np. apache/nginx), który jest wystawiony w świat i “proksuje” requesty od/do aplikacji w Pythonie (tu mocny PoC tej apki). Ta aplikacja z kolei używa bazy danych i cache w jednym, jakim jest redis do przechowywania informacji, sama wyłącznie generuje linki i zapisuje oraz pobiera (do/z redisa). Redis umożliwia tworzenie backupów swojej “pamięci” cache, którą oferuje, więc możemy go potraktować również jako swego rodzaju persystentną bazę, jest również bardzo skalowalny.
Marcin postuluje użycie logów usługi httpd do zliczania ilości odwiedzin danego shortlinka (shortlink - to skrócony link, który “zna” nasza aplikacja i którego użycie ona “zapisuje"a), np. za pomocą aplikacji typu awstats, goaccess czy innego analizatora logów, który umożliwia nam analizę logów do naszych celów, choć w ostateczności wystarczy odpowiedni skrypt w bashu, który może zrobić to samo.
Dobre strony (moim subiektywnym zdaniem). Marcin motywuje swój pomysł i zastosowane technologie prosto: użyciem odpowiednich i przetestowanych narzędzi, do odpowiednich celów. I tak httpd/loadbalancery i tak często “siedzą” na przodzie wielu takich aplikacji i tak produkują logi - wykorzystajmy więc te logi do zapewnienia części funkcjonalności (np. zliczanie odwiedzin), a sam httpd/LB stanowi bramkę, która przesyła requesty do aplikacji za nim, która będzie miała za zadanie sprawdzać/generować shortcody i zapisywać w cache/bazie danych. Obecność httpd/LB niejako z automatu ułatwia nam skalowanie - dodawanie kolejnych instancji aplikacji jest bardzo proste.
No i nie zapominajmy, że httpd/LB jest przetestowanym przez lata oprogramowaniem przez miliony projektów, więc też daje nam to pewien spokój pod względem bezpieczeństwa, choć i tak powinniśmy zwrócić pewną uwagę w naszej aplikacji za LB, na dane, które odbieramy, aby mieć większą pewność, że wszystko jest w porządku. Wydajność też tutaj nie jest problemem - httpd/LB są sprawdzone na tym polu, a ewentualna “powolna” aplikacja za httpd/LB może być prosto wyskalowana w razie potrzeby, no i mamy redisa.
Nieco o wadach (moim subiektywnym zdaniem, w stosunku do “mojej” architektury i stacku). Przyczepię się tutaj do redisa, który będzie robił za bazę danych klucz-wartość, zdecydowanie nie jest to technologia, która nam “przypilnuje” poprawności naszej bazy danych, bo do tego redis nie służy, tutaj na naszą aplikację spada największy ciężar weryfikowania danych, które wylądują w bazie w cache (to to samo tutaj). Druga sprawa, to “rozrzucenie” danych na redisa i logi httpd/LB. W sensie, redis tylko przechowuje linki, natomiast “resztę” danych dostarczą nam logi httpd/LB, co oznacza, że logi te są ważne i będą coraz większe i większe. Wraz z rozwojem aplikacji, rozumianym jako przyrost danych (linków) w niej, logów będzie coraz więcej i więcej i ogarnianie ich będzie albo karkołomne (skrypty/apki zliczające) lub bedzie wymagało wprowadzenia stosu typu ELK do aplikacji.
Podejście moje
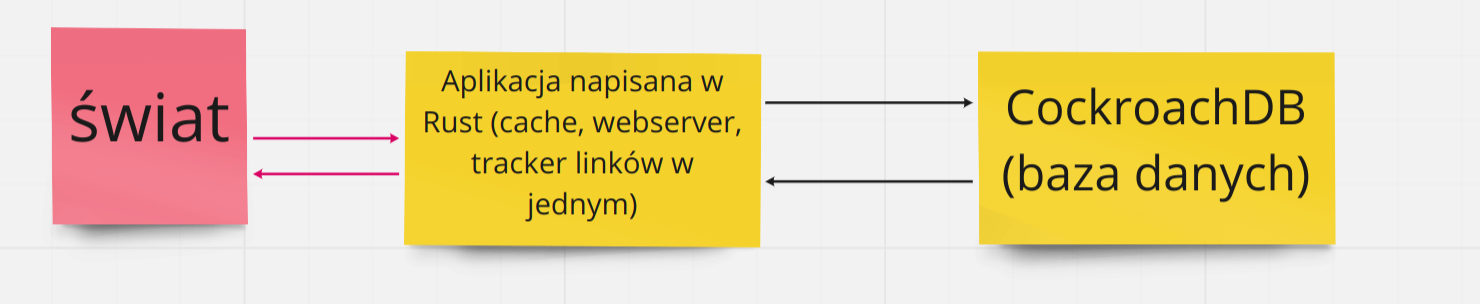
Aplikacja napisana w języku Rust, która sama dla siebie jest serwerem httpd (actix-web), korzysta z wewnętrznych mechanizmów cache (np. hashmapy) - bez stosowania rozwiązań zewnętrznych typu redis. Jako baza danych - CockroachDB, który jest wysoce skalowalną bazą relacyjną (podobną do PostgreSQL). To tyle jak chodzi o zastosowane technologie, nie ma więcej.
Jeśli chodzi o wady mojego rozwiązania, to wymienie je jako pierwsze, dla odmiany. Największa wada, to zdecydowanie fakt, że taka aplikacja będzie znacznie bardziej skomplikowana jak chodzi o jej funkcjonalność (pomijamy użycie języka, który do prostych również nie należy): trzeba zwyczajnie napisać i “przejąć” funkcjonalności takie jak zarządzanie shortlinkami (za to u Marcina odpowiada tylko jego PoC w Pythonie), zarządzanie cache (to mniejszy problem, bo na poziomie kodu może to wyglądać podobnie jak używanie rozwiązania zewnętrznego typu redis), odpowiednie logowanie (u Marcina zajmuje się tym httpd/LB). Generalnie skomplikowanie tej aplikacji wpływa tutaj na parametr TTM - Time to Market (czas, kiedy może coś takiego powstać), bo rozwiązanie zaproponowane przez Marcina można w miarę szybko i prosto “poskładać” i będzie jakoś działać, tutaj się tak nie da.
Druga wada: Rust jest bardzo młodym językiem i to działa na jego niekorzyść w niektórych sytuacjach, np. rozwiązania httpd/LB obecne na rynku od lat są pewne i przetestowane, a Rustowe frameworki webowe są jeszcze zbyt młode, by mieć taką renomę. Po prostu, jak chodzi o stabilność, znacznie pewniej tutaj postawić na nginksa napisanego w C, niż na webserver napisany w Rust. Jak również, w przypadku ewentualnych problemów, prędzej znajdziemy pomoc lub specjalistów, jeśli napotkamy na problemy z apache/nginx, aniżeli jeśli problemy przydarzą nam się np. z actix-web w Rust.
Zalety. Jeżeli aplikacja już powstanie, to z racji użycia Rusta, to będzie jedna statyczna binarka, CockroachDB to z kolei baza napisana w Go, zatem również jedna statyczna binarka. Mamy więc dwa pliki, które są naszą całą aplikacją (pomijam tu pliki z danymi bazy danych). Zatem mamy prawdziwą prostotę jak chodzi o deployment.
Zastosowana jest normalna, relacyjna baza danych, która dobrze się skaluje (to jej główna cecha). Dzięki obecności takiej bazy danych możemy mieć pewność, że nasze dane, jeśli muszą podlegać zadanym regułom, to tylko takie dane będą się w tej bazie znajdować, a zatem baza sama może tu zadbać o to, by nie posiadała śmieciowych danych (zakładając, że przyłożymy się do poprawnego zdefiniowania tabel).
I sama persystencja danych - CockroachDB jest w pełni zgodny z zasadami ACID, to oznacza, że jeśli baza danych nas poinformuje, że dane zapisała, to tak w istocie jest i raczej nie musimy się obawiać już o ich ewentualną utratę.
No i dzięki temu, że mamy “zwykłą” bazę to nigdy w tym rozwiązaniu nas nie zaboli głowa, jeśli będziemy chcieli dokładniejsze statystyki sprzed nawet długiego okresu czasu - moim zdaniem jest tu spory kontrast w stosunku do “wygrzebywania” statystyk z logów httpd.
Podsumowanie
Starałem się te dwie architektury w miarę obiektywnie przedstawić, ale nie jest wykluczone, że coś przekręciłem lub ilość znaków dla wad/zalet różni się, dlatego słowo-klucz starałem się.
Jak widać, obydwa rozwiązania mają swoje wady i zalety, jak wszystko. To do Was, czytelników, zależy ocena, które rozwiązanie podoba Wam się bardziej w takiej sytuacji. Możecie dać znać w komentarzach.
Ze swojej strony mogę jedynie dodać, że gdybym pracował w jednym projekcie z Marcinem i miał za zadanie, zaprjektowanie architektury dla takiej właśnie aplikacji, to bez zastanowienia zastosowałbym jego wersję architektury z tego względu, że obaj równie komfortowo czulibyśmy się w tym rozwiązaniu, tj. z mojego punktu widzenia, jego architektura posiada podejścia i technologie, które ja sam znam i rozumiem. Nie wiem czy podobnie byłoby w drugą stronę, nie będę tu wypowiadał się za Marcina, ale pamiętajcie, że lepiej pracować drużynowo i czerpać z tego korzyści, aniżeli budować swoje własne okopy w projektach, o które wszyscy się później potykają.